Generative techniques like Stable Diffusion have been out for a while and are starting to make their way into the field of remote sensing. I thought I’d give these models a try and see what the hype was all about. From my very brief experiments, I can say two things: one, I’m not entirely sold on the utility of generative models for real world applications; two, these models make interesting and abstract art that resembles remote sensing imagery. Until these models and their supporting ecosystem develop further to allow practical application development, I’ll simply spend my time toying with these models to generate interesting art pieces.
Base Knowledge
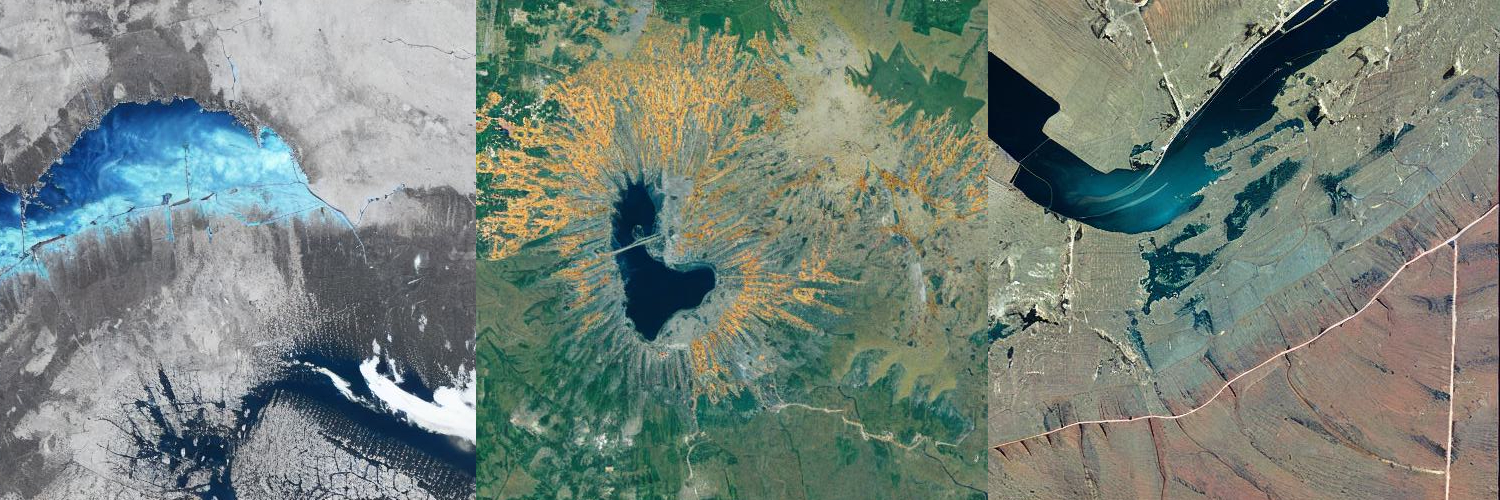
Interestingly, pretrained Stable Diffusion (SD) models have a built in understanding of satellite imagery. These models are pretrained on LAION-5B, which includes both captioned arial and satellite imagery. I asked baseline SD1.5 and SDXL models to create “satellite images of mountains,” and this is what they produced:

Not too bad for models with no finetuning. I found SD1.5 to be fairly opinionated and reliant on it’s original training images when generating satellite images. SD1.5 tends to apply perspectives and features of normal mountain photography onto images that have the vantage point of a satellite. This makes for fairly unnatural looking images. SDXL, on the other hand, has the advantage of being a bigger model and appears to have a better base knowledge of what a satellite image should look like. XL doesn’t force as much stylization or awkward perspectives as 1.5.
Finetuning
I wanted to see if finetuning these models on a remote sensing dataset would yield anything different or, hopefully, better. I took a similar approach as this article and used part of the AID dataset to finetune on a single class: satellite images of mountains. I stuck to LoRA finetuning since I only have a plebe graphics card with limited memory. This, however, is where LoRAs shine and allow people with consumer hardware to dive into the world of generative models.
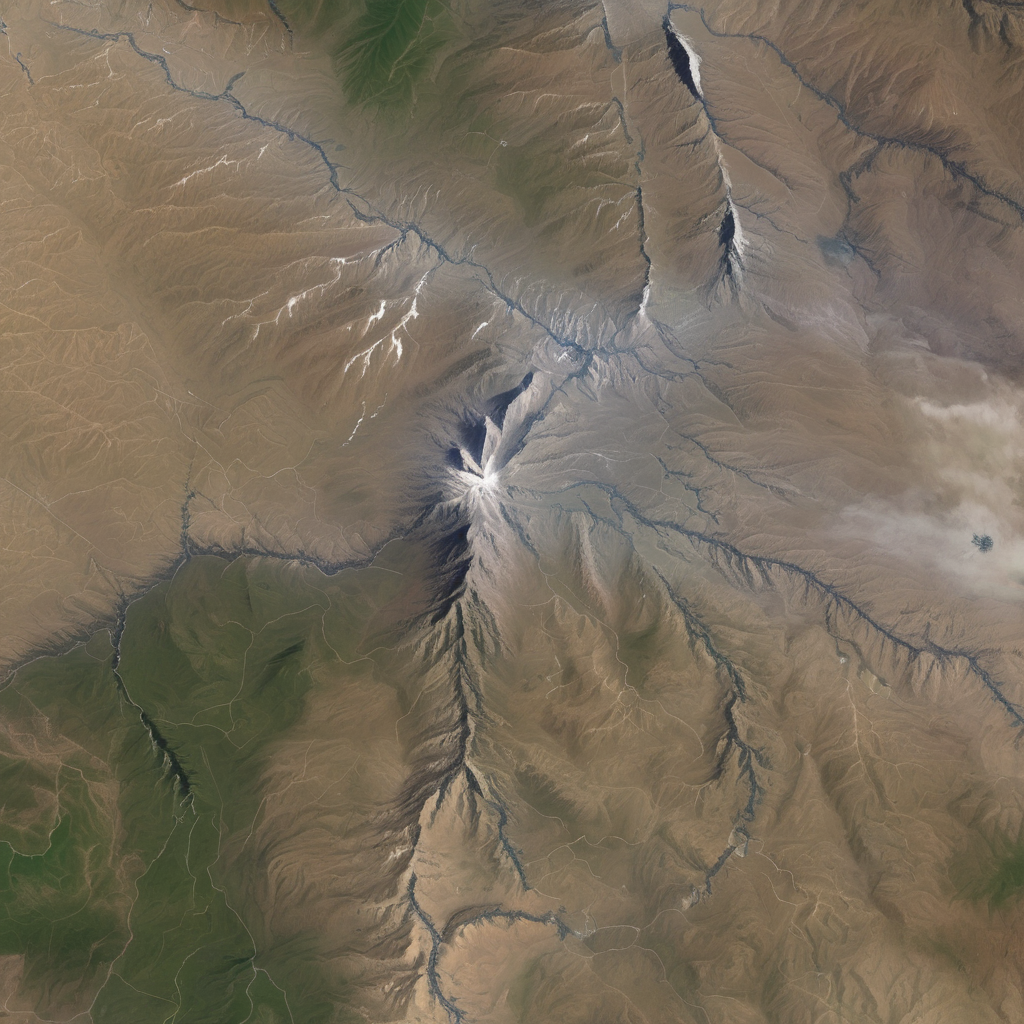
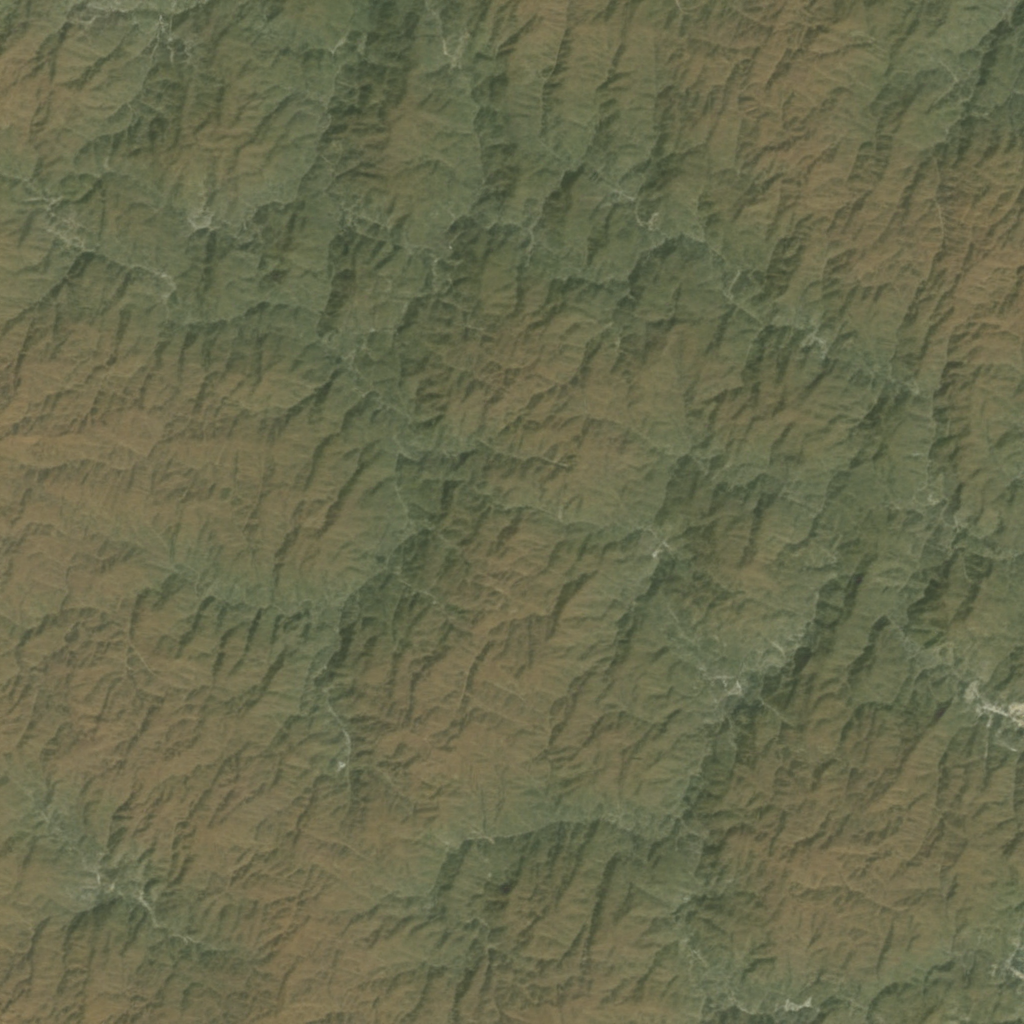
The constrained influence of trained LoRA weights was, intriguingly, different for SD1.5 and SDXL. 1.5 no longer suffered from strange perspectives and was largely able to stick to a top-down view of mountain ranges. Some of the high contrast and bright colors, however, still remain.
The XL model was much more receptive to the finetuning dataset. While the output is not necessarily artistic, it does better represent the distribution of the AID images. In other words, the mountain images generated by SDXL look like they could have come from the AID dataset.

Thoughts
I didn’t do a whole lot of hyperparameter tuning. It may very well be the case that the difference I saw in 1.5 and XL was due to differences in model and training hyperparameters. I’m also curious about how fully retraining either model on the complete AID dataset would compare to the examples I’ve posted here. Perhaps a follow up post is warranted.
In the meantime, I’ll wrap up with a thought that stuck with me during this whole process: is there an actual use case for generative models in remote sensing? One thing that is immediately clear to me is that there is still a significant barrier to achieving reliable outputs that would serve a meaningful purpose in production environments. Synthetic data is only as good as the training data used to create the generator model. A LOT of data is needed to get really good results. I would argue that high quality labeled data is better used for training a non-generative model for a specific task or application. Even though the outputs of SD variants can be impressive and realistic, I still don’t see what this generated imagery would be really used for remote sensing applications. What am I going to do or make with more images of roads or stadiums?
I’m confident these models will get better in the future and I may even be proven wrong that more images of roads are, in fact, better for training down-stream models. In the meantime, the effort used to train and customize these models is probably better used on curating high quality datasets for much smaller models aimed at reliably tackling a specific task. Until the generative landscape makes another tectonic shift, I’ll be using these models for what they do best: making art.




Code
I’ve created a repository with an example implementation of finetuning SD1.5 with LoRA. I rely heavily on Huggingface’s finetuning template and have modified the script to work with my RTX3060. The Dockerfile and Makefile should allow you to quickly get started with finetuning the model if you have the same card and the same CUDA drivers as those defined in the Dockerfile. The only other prerequisite is downloading the AID dataset and creating a custom jsonl file to point to the images and define the training captions.